Enterprise Service Management
Eine der neuesten Entwicklungen ist der Übergang von einem rein IT-zentrierten Ansatz hin zum Enterprise Service Management (ESM). ESM erweitert die Grundprinzipien des ITSM, um nicht nur IT-Dienste, sondern auch andere betriebliche Bereiche wie HR, Marketing, Finanzen und Facilities Management zu unterstützen.
Ein Aspekt, der die Integration von ESM in die ITSM-Praxis vorantreibt, ist die fortschreitende Digitalisierung und der Einsatz neuer Technologien. Mit der Einführung von Automatisierung, künstlicher Intelligenz (KI) und Self-Service-Portalen können Unternehmen schnelle Lösungen für interne Anliegen bereitstellen und proaktive Unterstützung anbieten. Diese Technologien führen dazu, dass Mitarbeiter effizientere Arbeitsabläufe erleben und die allgemeine Kundenzufriedenheit steigt. ESM hilft Unternehmen, ihre Dienstleistungen als ganzheitliches System zu verstehen, was eine bessere Koordination und Unterstützung über alle Bereiche hinweg ermöglicht.
KI ist auch in ITSM angekommen
Durch die Integration von künstlicher Intelligenz automatisieren Sie repetitive und zeitaufwändige Aufgaben, wodurch IT-Teams entlastet werden und sich verstärkt auf strategische Projekte konzentrieren können. KI-gestützte Tools sind in der Lage, Anfragen von Nutzern zu analysieren, Muster zu erkennen und automatisch Lösungen anzubieten, was die Reaktionszeiten erheblich verkürzt und die Effizienz steigert.
Ein weiterer innovativer Aspekt von KI im ITSM ist die Verbesserung der Benutzererfahrung durch personalisierte Services. Virtuelle Assistenten helfen, häufige Anfragen schnell und effizient zu bearbeiten, was zu einer höheren Zufriedenheit der Endanwender führt.
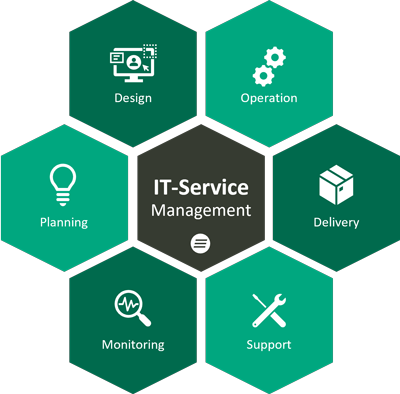
Das IT Service Management (kurz ITSM) ist die Bereitstellung der IT als Service – für Mitarbeiter und Kunden. Dazu gehören alle Prozesse und Aktivitäten rund um die Planung, Zusammenstellung, Lieferung und den Support von IT-Services.
Das Ziel von ITSM-Systemen ist es dabei, Menschen, Geschäftsprozesse und die IT innerhalb des Unternehmens bestmöglich zu verknüpfen, Zeit sowie Kosten zu sparen und so die Produktivität und Wirtschaftlichkeit im Unternehmen zu erhöhen.
Kurzum soll ITSM dabei helfen, Unternehmensziele und -erwartungen zu erreichen und Abläufe zu vereinfachen. Darüber hinaus helfen ITSM Systeme dabei, die immer komplexeren IT Landschaften, IT Services und Prozesse leichter zu managen und wo möglich zu automatisieren.
Heute geht ITSM sogar noch einen Schritt weiter. Anstatt neue Anwendungsbereiche und Einsatzgebiete abzuwarten, nutzen viele ITSM-Tools bereits die Vorteile von Machine Learning und Künstlicher Intelligenz (KI), um solche Anforderungen möglichst genau vorhersagen zu können, noch bevor sie eingehen.
IT-Teams sind für den gesamten IT-Betrieb zuständig – von neu benötigten oder beschädigten Laptops über fehlerhafte Server bis hin zu geschäftskritischen Softwareanwendungen und vergessenen Passwörtern sowie die Verwaltung und Überwachung aller relevanter Unternehmen-Assets, wozu durchaus auch NON-IT Assets gehören.
Und ITSM bietet die beste Lösung dafür. Denn es gibt genau die Art und Weise vor, wie IT-Teams die Bereitstellung von jenen Services für Kunden sowie Mitarbeiter verwalten und organisieren müssen, damit jeder im Betrieb störungsfrei arbeiten kann.
Umgekehrt können Mitarbeiter und Kunden dank ITSM problemlos mit dem IT-Team kommunizieren und so Probleme und Anfragen punktgenau übermitteln. Im Gegensatz zum traditionellen IT-Support, der lediglich technische Hilfsmittel zur Verfügung stellt, streben ITSM-Lösungen danach, einen umfassenden und vor allem einfachen Service zu bieten, der den internen Kunden effektiv unterstützt. So kann das IT-Team einen messbaren Wertbeitrag zum Unternehmenserfolg liefern.
Warum ist IT Service Management wichtig?
Die Digitalisierung, hybride Arbeitsmodelle und die zunehmende Vernetzung von Abteilungen in modernen Unternehmen fordern heutzutage ein effizientes IT Service Management. Dabei wird eine effiziente Verwaltung von IT-Services – idealerweise in Echtzeit – sowohl von Mitarbeitern als auch von Kunden erwartet.
Anders formuliert: Sobald Sie irgendein IT-Service oder Produkt anbieten und eine positive Prozesseffizienz anstreben, sollten Sie sich mit ITSM beschäftigen. Denn nur über ITSM kann die IT punktgenau auf die Anforderungen eines Unternehmens samt Kunden und Mitarbeitern reagieren.
ITSM-Frameworks, Normen und Standards
Was ist ein ITSM-Framework? Damit Sie im dynamischen IT-Umfeld zwischen ständig neuen Anforderungen, Technologien und Beteiligten nicht den Überblick verlieren, gibt es sogenannte Frameworks, die im ITSM eine Struktur vorgeben. Zudem gibt es Zertifizierungen und Normen wie die ISO/IEC 20000, die die Mindestanforderungen an das IT Service Management enthalten.
IT-Teams nutzen eine Vielzahl von Frameworks, an denen ihre Arbeit ausgerichtet ist. Zu den am häufigsten verwendeten zählen ITSM und DevOps. Es gibt aber zahlreiche andere Konzepte wie COBIT, SIAM, IT4IT, ITIL und Lean, um nur einige zu nennen. Wir listen Ihnen hier die beiden Wichtigsten auf.
ITIL
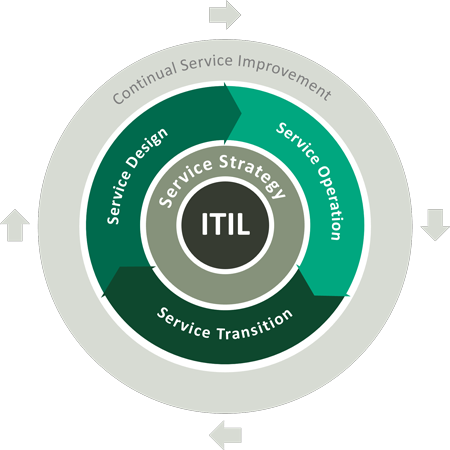
Die Begriffe ITSM und die Information Technology Infrastructure Library (kurz ITIL) werden gerne synonym verwendet, obwohl sie nicht dasselbe sind. ITIL ist ein Framework, das innerhalb von ITSM zu finden ist. ITIL hat als Hauptfokus die Verbesserung der Effizienz und der Vorhersehbarkeit und ist im Grunde ein Leitfaden, der Unternehmen unter anderem bei der Einführung von ITSM unterstützt.
ITIL ist kurz gesagt eine allgemein anerkannte Reihe von Best Practices, die eine Organisation dabei unterstützen soll, durch die Ausrichtung von IT-Services an der Geschäftsstrategie den größtmöglichen Nutzen aus der IT zu ziehen. Dafür werden Methoden wie Checklisten, Tasks und Prozesse verwendet, die jedes Unternehmen problemlos implementieren kann.
Zusammengefasst kann man sagen, dass ITIL-Prozesse Teil von ITSM sein können, aber nicht jedes ITSM auf alle in ITIL definierten Standards zurückgreift oder diesen folgt.
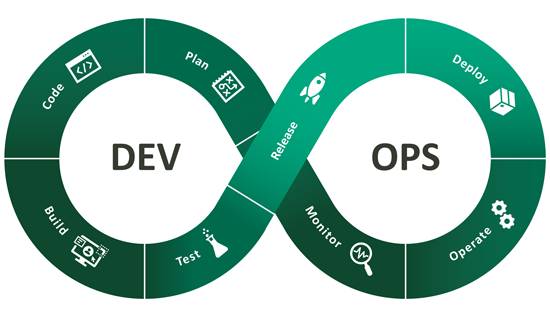
DevOps
DevOps und ITIL werden oft in Konkurrenz zueinander genannt, das stimmt so jedoch nicht ganz: DevOps ist eine Methode zur Überwindung der Kluft zwischen Entwicklung (Development) und Betrieb (Operations).
Die Kernprinzipien sind offene Kommunikation, Zusammenarbeit und gemeinsame Ziele. DevOps und ITIL schließen sich daher nicht gegenseitig aus, sondern können einander ergänzen. Der Unterschied liegt vor allem darin, dass DevOps keine Prozessrichtlinien bietet, wie es ITIL vorgibt. Es gibt unzählige Anwendungsfälle für DevOps und ITIL, wie zum Beispiel:
- die Beschleunigung neuer Releases
- das Vorbeugen von Incidents
- die Analyse von Incidents
- Empfehlungen für den Systemaufbau von Ticketing, Change und Problem Management
- Predictive Maintenance
- Sicherstellung der Aktualität von Systemen
- und vieles mehr
Nun wissen Sie, was ITSM ist, was es leistet und welche Frameworks damit einhergehen können. Doch welche Vorteile hat die Implementierung eines IT Service Managements konkret für Ihr Unternehmen?
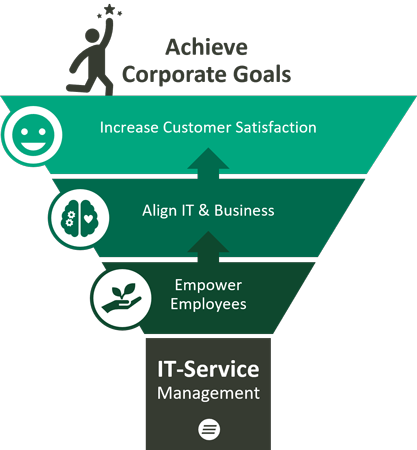
Die wichtigste Aufgabe von ITSM-Software ist die Verbesserung der Effizienz und der Produktivität eines Unternehmens. Denn das ITSM-System reduziert Kosten und vermindert Risiken, während gleichzeitig alle Prozesse im Unternehmen vorhersehbarer und planbarer werden. Und dieser verbesserte Service führt schließlich auch zu besseren Kundenerfahrungen, was sich wiederum positiv auf die Geschäftszahlen auswirkt.
Um das zu gewährleisten, fungiert das IT Service Management als Bindeglied zwischen Endnutzern von IT-Services und IT-Fachleuten. Der Schwerpunkt liegt also weniger auf den Systemen an sich, sondern mehr auf den praktischen, unternehmensseitigen Anforderungen. Grundlegende Vorteile, die sich aus der Implementierung von ITSM ergeben, sind die folgenden:
ITSM legt den Hauptfokus auf die Planung und das Management der IT-Services eines Kunden oder der Mitarbeiter innerhalb eines Unternehmens. Das passiert durch kontinuierliche Analyse und Verbesserung der vorhandenen Prozesse, IT-Services und Infrastruktur.
Dazu gehören alle Prozesse und Aktivitäten rund um die Planung, Zusammenstellung, Lieferung und den Support von IT-Services. ITSM ist also serviceorientiert. Das zentrale Konzept ergibt sich aus der Überzeugung, dass die IT als Service bereitgestellt werden sollte, um wirtschaftlich agieren zu können.
Neben diesen allgemeinen Vorteilen hat ITSM noch weitere Benefits für das Unternehmen und die IT-Abteilung selbst zu bieten, die wir Ihnen im Folgenden auflisten:
Vorteile für das Unternehmen
Die Einrichtung von ITSM-Prozessen und die Anschaffung einer IT-Service-Management-Software ist natürlich mit einem einmaligen Kapitalaufwand (CAPEX) verbunden. Sie werden jedoch aufgrund der vielen hier genannten Vorteile schnell eine höhere Kapitalrendite (ROI) erzielen, da Sie wiederkehrende Betriebskosten (OPEX) einsparen. Konkret können Unternehmen wie folgt von ITSM profitieren:
Vorteile für die IT
Doch nicht nur für das Unternehmen hat ein ITSM-System positive Auswirkungen, auch die IT selbst profitiert von der Einführung.
Um diese Vorteile auch wirklich nutzbar zu machen, bietet IT Service Management eine Vielzahl an Prozessen, auf die wir nun eingehen werden. Vorneweg ist noch zu sagen, dass dabei nicht alle Prozesse im Unternehmen etabliert werden müssen, sondern nur jene, die den spezifischen Anforderungen des Unternehmens entsprechen.
Kaum ein Unternehmen kommt heutzutage ohne Technologie aus: Vom Laptop, über die darauf installierten Anwendungen, den Server bis hin zum Drucker. All diese Devices sind für die tägliche Arbeit unabdingbar und wenn sie nicht funktionieren, dann stocken oft ganze Abteilungen.
Dabei lange Ausfallzeiten zu vermeiden, obliegt oft der IT, an die die meisten Anfragen dieser Art über einen sogenannten Service Desk übermittelt und später abgewickelt werden. Neben dem Management von Serviceanfragen werden dabei auch ITSM-Aktivitäten wie das Vorfallmanagement, das Wissensmanagement, Self-Service, Berichterstellung u. v. m. bearbeitet. Welche Prozesse mittels ITSM im Allgemeinen ausgelöst werden können, erfahren Sie jetzt.
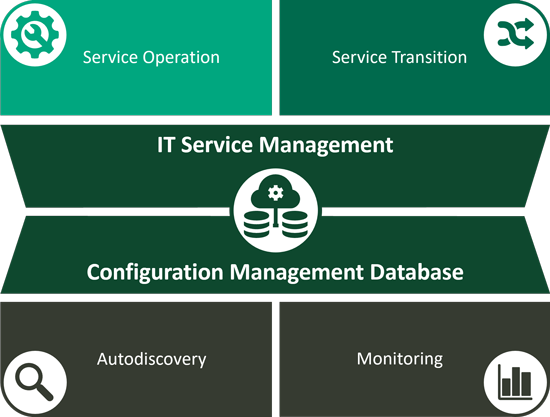
Configuration Management Database (CMDB)
Eine Configuration Management Database (CMDB) speichert Informationen über die Konfiguration von Elementen innerhalb eines Unternehmens, einschließlich Hardware, Software, Systeme, Einrichtungen und manchmal auch Personal. Somit bildet die CMBD die zentrale Schnittstelle im ITSM, denn auf diese Datenbank greifen alle Prozesse im ITSM zu.
Das Ziel einer CMDB ist es daher, die Informationen bereitzustellen, die ein Unternehmen benötigt, um bessere Geschäftsentscheidungen zu treffen und ITSM-Prozesse effizient auszuführen. Durch die Zentralisierung aller Konfigurationsinformationen können Führungskräfte kritische Configuration Items und ihre Beziehungen besser verstehen.
Das passende ITSM-System finden
Welche Vorteile ITSM im Unternehmensalltag bringt und welche Prozesse es grundsätzlich umfasst, haben wir oben aufgeführt. Um Ihren individuellen Unternehmensanforderungen gerecht werden zu können und um eine ITSM Lösung passgenau einzuführen, stellen sich darüber hinaus folgende Fragen:
- Welches Problem möchte ich lösen?
- Was fehlt bei Ihren momentanen ITSM-Prozessen?
- Was können Sie tun, um Ihre IT-Serviceleistungen zu verbessern?
- An welchen Punkten kommt das ITSM-Tool zum Einsatz?
- Welche Voraussetzungen sind durch mein Unternehmen gegeben?
- Ist eine Zusammenarbeit entlang der zentralen Prozesse auch über Abteilungsgrenzen hinweg gegeben?
- Kann es bei Bedarf an neue Anforderungen angepasst werden?
- Können alle relevanten Unternehmens-Assets effektiv verwaltet werden und erfüllen bisherige Abläufe ihre Compliance-Vorgaben?
- Möchten Sie ein Self-Service-Portal ins Leben rufen?
- Was erwarte ich von einem neuen ITSM-Tool?
- Werden Assets im Rahmen einer kritischen Infrastruktur überwacht und inwieweit soll dies durch die ITSM Lösung übernommen werden (Lifecycle Management, KRITIS)?
Zusätzlich sollten Sie sich auch über die folgenden 2 Aussagen Gedanken machen:
- Wenn Sie z. B. weiterhin mit verschiedenen Anwendungen arbeiten möchten, sollte das neue Tool über Schnittstellen für deren Anbindung verfügen.
- Bei einer großen Anzahl an Workflows benötigen Sie ein Tool mit Workflow-Automatisierung.
Sie sehen also: ITSM-Systeme sind modular und können je nach Bedarf einzeln in Ihr Unternehmen integriert werden. Um für Ihren Workflow dabei das Maximum herauszuholen, sollten Sie sich umfassend beraten lassen. Einige Anbieter, wie auch wir, bieten kostenlose Testläufe an. Auch der Austausch mit Partnern, anderen Unternehmen oder Kunden kann Ihre Entscheidung erleichtern.
ITSM im Unternehmen umsetzen: Best Practice in 6 Schritten
Beachten Sie: Eine erfolgreiche Einführung von ITSM benötigt die Unterstützung von IT-Stakeholdern UND Unternehmens-Stakeholdern. Das bedeutet, es ist von zentraler Wichtigkeit, die Relevanz von ITSM im Unternehmen zu kommunizieren.
Die Einführung selbst bedarf einer genauen Planung der wichtigsten Erfolgsfaktoren, sowie die Kontrolle selbiger mittels regelmäßig überprüfter Kennzahlen. Eine prinzipielle Möglichkeit, Unternehmen bei der erfolgreichen Implementierung von ITSM zu beraten, besteht darin, sich laufende IT-Prozesse anzuschauen (zum Beispiel „neuer Mitarbeiter“), diese zu verfolgen und in mehrere Schritte zu unterteilen und zu digitalisieren. Das grundlegende Vorgehen dabei sieht wie folgt aus:
Wenn man in Richtung Zukunft von ITSM blickt, ist der Aufstieg von sogenannten AIOps zu beobachten. Der Begriff AIOps setzt sich dabei aus Artificial Intelligence, AI, und dem Management von IT Operationen, Ops, zusammen. Dabei wird künstliche Intelligenz zu Hilfe genommen, um operationale Schwierigkeiten (beispielsweise Systemausfälle) zu melden, zu lösen oder nach Möglichkeiten zu suchen, um wiederum mit der steigenden Komplexität der Technologien Schritt halten und sie managen zu können.
Einer der wichtigsten Aufträge an AIOps ist die Integration unterschiedlichster Datensilos aus ITSM und IT-Operation-Management. Durch diese Zusammenführung der Daten fällt es zunehmend leichter, die Ursachen vieler Probleme schneller und effizienter zu entdecken und somit zu beheben. Gleichzeitig hilft es auch, Automatisierung überhaupt erst zu ermöglichen, da es nur noch einen einzigen Datenpool gibt, statt einzelner Silos. Wie bei vielen Technologien liegt auch die Zukunft des ITSM in der KI, also in der Künstlichen Intelligenz. Durch die Automatisierung zahlreicher Bereiche, …
- wie automatisierte Kommunikation,
- Ticketlösung,
- automatischer Auslastungsoptimierung und
- präventiver Wartung von Systemen
… kann viel Zeit eingespart werden. Denn KI kann die Infrastruktur des Service-Desks permanent überwachen und Störfälle frühzeitig erkennen und melden.
ITSM: Profitieren Sie noch heute von IT Service Management
ITSM kommt nicht nur Ihrem IT-Team, sondern Ihrem gesamten Unternehmen zu Gute. ITSM führt richtig verwendet immer zu einer Effizienz- und Produktivitätssteigerung. Denn ein strukturierter ITSM-Ansatz ermöglicht die Ausrichtung der IT auf Geschäftsziele und standardisiert die Bereitstellung von Services basierend auf Budgets, Ressourcen und Ergebnissen – für Mitarbeiter und Kunden. So werden Kosten reduziert und Risiken minimiert, was letztendlich das gesamte Unternehmen und seine Außenwirkung positiv beeinflusst.